Der folgende Artikel beschäftigt sich mit der konkreten Umsetzung der Reduktionsverfahren anhand der Codecs der MPEG.
Audiocodierung nach MPEG
Die Motion Pictures Expert Group (MPEG) hat in den vergangenen Jahren eine ganze Reihe von Codecs für Audio- und Videosignalevorgestellt. Im folgenden soll näher auf MPEG Audio und MPEG 2 eingegangen werden. Der MPEG Audio Codec wird in mehrere Unterstandardsaufgegliedert, die als Layer 1, 2 bzw Layer 3 bezeichnet werden. Eine der ersten konkreten Anwendungen von MPEG Audio Layer-1 inSeriengeräten war die mittlerweile nicht mehr produzierte DCC (Digital Compact Cassette). MPEG Audio Layer-1 sowie die Weiterentwicklung Layer-2 werden heute im digitalen Rundfunk (DAB und DVB) eingesetzt.MPEG Audio Layer-3, im Volksmund besser bekannt unter dem Namen MP3, wurde maßgeblich im deutschen Forschungslabor des Fraunhofer Institutes in Erlangen entwickelt unddient der starken Kompression von Audiosignalen zur Übertragung über Kanäle, deren maximal zulässige Datenrate sehr beschränkt ist. Die Audioübertragung per Internet stellt heutedie häufigste Anwendungsform von MP3 dar.
Die Codierung nach MPEG Audio richtet sich bei allen Layern grundlegend danach, welches Eingangssignal anliegt. Man unterscheidet die folgenden Optionen:
- Single Channel Coding:
Zur Kompression von Monosignalen
- Dual Channel Coding:
Zur Kompression von Zweikanalton, eine mögliche Anwendung sind hier zweisprachig zu übertragende Fernsehsendungen
- Stereo Coding:
Codierung von Stereosignalen, beide Stereokanäle werden vollständig separat codiert
- Joint Stereo Coding:
ebenfalls Codierung von Stereosignalen, aber hier unter Herausrechnung der Redundanz zwischen beiden Kanälen
Alle Layer von MPEG Audio basieren auf dem Subband Coding, das je nach Layer mehr oder weniger aufwendig implementiert ist.Die folgende Abbildung zeigt den allen Layern zugrunde liegenden Teil des MPEG Audio Encoders:
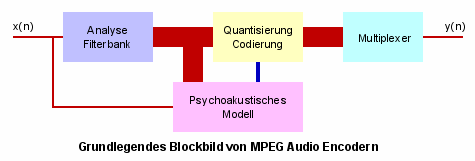
Zunächst sorgt eine Analysefilterbank für die Aufgliederung des Frequenzbereiches des PCM-Eingangssignals inUnterbänder. Diese Unterbänder werden mit Hilfe einer Schaltung, die die globale Verdeckungsschwelle des Eingangssignals nach dem Psychoakustischen Modell errechnet, einzeln analysiert. Die Schaltung bestimmt die Bereiche innerhalb der Unterbänder, die ohne größere Qualitätsverluste herausgerechnet werden könnenund stellt anhand des Ergebnisses die Bitrate des Quantisierers auf den optimalen Wert ein. Das Ziel beim Quantisierungsprozess ist das Quantisierungsrauschen unterhalb der globalen Verdeckungsschwelle zu halten, gleichzeitig aber eine geringe Bitrate zu erreichen.
Allerdings wird die Reduktion der Bitrate meißt nicht bis ans äußerste Limit getrieben. Der Coder versucht nicht nur die Bitrate so hoch zu halten, dass keine Artefakte aufgrund hörbaren Quantisierungsrauschens entstehen, sondernpasst gleichzeitig die Bitrate an die verfügbare Übertragungskapazität des verwendeten Datenkanals an. Stehen zur Übertragung beispielsweise über Rundfunk mehr Bit/s zur Verfügung als für das maximal datenreduzierte Signal nötig,so wird nicht mit minimaler Bitrate codiert, sondern diese soweit hochgefahren, bis die Übertragungskapazität voll ausgelastet wird.Wozu dieser Aufwand? Um diese Frage zu beantworten muss man sich klar machen, dass das Quantisierungsrauschen bei maximaler Datenreduktion durch einen MPEG-Coder das Musiksignal gerade noch nicht stört.Wird allerdings der Frequenzgang durch nachfolgende Elektronik verändert (z.B. Equalizer), ändert sich auch die globale Hörschwelle und das Quantisierungsrauschen kann bei allzu eng kalkulierter Bitrate hörbar werden.Gleicher Effekt tritt übrigens auch dann auf, wenn man ein MPEG-codiertes Signal abtastet und anschließend nochmals quantisiert. Durch diesen zweiten Quantisierungsprozess wird neues Rauschengeneriert, dass sich dem Quantisierungsrauschen aus dem MPEG-Codierungsprozess additiv überlagert. Das Quantisierungsrauschen steigt dann unter Umständen über die Hörschwelle undwird damit wahrnehmbar. Aus diesem Grund sollte die Datenrate der zur Verfügung stehenden Übertragungskanäle möglichst optimal ausgenutzt werden, um Fehler bei der Weiterverarbeitung des MPEG-Signals in nachfolgender Elektronikauszuschließen.
Der abschließende Multiplexer verschachtelt die einzelnen Bänder in einen MPEG-Audio Datenstrom, der von einem entsprechenden Decoder wiederentschlüsselt werden kann. Nachdem nun der grundlegende Aufbau von MPEG-Codern dargestellt wurde, soll im folgenden auf die spezifischen Eigenschaften der einzelnen Layer näher eingegangen werden.
Codierung nach MPEG Audio Layer-1:
In der folgenden Abbildung sehen Sie den groben Aufbau eines MPEG Audio Layer-1 Coders anhand eines Blockbildes. Die Signalwege sinddunkelrot, die Wege der Steuersignale dunkelblau dargestellt.
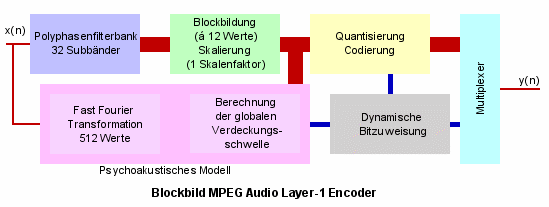
Im MPEG Audio Layer-1 Coder erfolgt die Verarbeitung des PCM-Eingangssignals x(n) abschnittsweise. Dazu wird das eintreffende digitale Signalin einzelne Frames konstanter Länge (384 PCM-Abtastwerte) aufgespalten. Das einzelne Frame wird anschließend durch eine Polyphasenfilterbankin 32 Frequenzbänder gleicher Breite zerlegt. Jedes Band besteht nun aus 384/32 = 12 einzelnen Abtastwerten.Wurde das ursprüngliche PCM-Signal, wie im professionellen Bereich üblich, mit 48kHz abgetastet, so entsprechen 12 Abtastwerte einer Signaldauer von 8ms.Die einzelnen 12 Signalwerte innerhalb eines Blockes werden anschließend verglichen und das Signal mit maximalem Wert bestimmt.Dieses Signal, der sogenannte Skalenfaktor, ist wichtig im Bezug auf die Maskierungsschwelle nach dem psychoakustischen Modell.Da der Block im Zeitbereich nur 8ms lang ist, das lauteste Signal des Blockes jedoch alle Signale die innerhalb eines Zeitfensters von 20ms liegen maskiert, beeinflusst bzw. verdeckt der Skalenfaktor die anderen Signale innerhalb des Blockes.Der Skalenfaktor selbst ist dagegen gut hörbar und wird daher mit hoher Bitrate (6Bit) direkt quantisiert. Die restlichen 11 Abtastwerte des Blockes werden auf den Skalenfaktor normiert, d.h. es wird die Höhe des Unterschiedes zwischen dem Skalenfaktor und den anderen Signalwerten des Blockes bestimmt. Der Unterschied ist eine der grundlegenden Informationen, aus denen das Psychoakustische Modell mit Hilfe der globalen Verdeckungsschwelle dieoptimale Bitrate errechnet. Anschließend stellt die Schaltung den Quantisierer über die dynamische Bitzuweisung optimal für die Quantisierung der 11 Signalwerte ein. Auch die maximale Übertragungsrate des Kanals, über den das MPEG-Signal einmal verschickt werden soll kann hier mit berücksichtigt werden.
Wie jedoch wird die globale Verdeckungsschwelle selbst bestimmt? Im Bereich mittlerer und hoher Frequenzen würde die spektrale Auflösung der Polyphasenfilterbank ausreichen, umdirekt aus den Blockwerten die globale Hörschwelle zu bestimmen. Nicht aber im Bereich tiefer Frequenzen. Man verwendet daher eine andere Vorgehensweise.Die Schaltung, die das psychoakustische Modell implementiert, betrachtet das PCM-Eingangssignal vor der Zerlegung in Blöcke. Mit Hilfe einer Fast Fourier Transformation (FFT, 512 Abtastwerte) wird das Eingangssignal vom Zeit- in denFrequenzraum transformiert um es dort einfacher und genauer analysieren zu können. Die FFT hat den Vorteil, dass sie auch im Bereich tiefer Frequenzen hohe Auflösung mit sich bringt. Im Frequenzbereich werden die Maxima des Audiosignals und deren Einfluss auf benachbarte Signale bestimmt. Das Ergebnis ist die sogenannte Signal To Mask Rate (SMR). Diese gibt an, in welchemVerhältnis das eigentliche Signal zur globalen Verdeckungsschwelle steht. Aus diesem Verhältnis folgt die Wahrnehmbarkeit des gerade zu codierenden Signalabschnitts und damit die optimalen Justageinformationen für den Quantisierer.
Der letzte Schritt bei der MPEG Audio Layer-1 Codierung ist die Verschachtelung der gewonnenen Daten der Subbänder in einen Datenstrang. DieseArbeit übernimmt ein Multiplexer, der nicht nur die Audiodaten zusammenfasst, sondern auch Steuerdaten und Informationsdaten über die Zusammensetzung des MPEG-Datenstrangs in den Ausgangsbitstromintegriert. Diese Information wird für den Decodierungsprozess im Endgerät benötigt.
Die Kompressionsrate des MPEG Audio Layer-1 Coders ist recht hoch. Für ein Monosignal liegt die minimale Bitrate bei 32kBit/s. Soll allerdings CD ähnliche Qualität erreicht werden, so muss die Datenrate auf bis zu 192kBit/s erhöht werden. Liegt Stereo an, so verdoppelt sich die Datenrate auf 384kBit/s (2 Signalkanäle mit je 192kBit/s). Zum Vergleich: ein unkomprimiertesPCM-Stereosignal in CD-Qualität besitzt eine Datenrate von 1,4Mbit/s.
Codierung nach MPEG Audio Layer-2
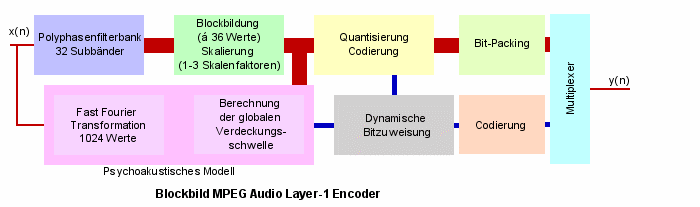
Der Encoder nach MPEG Audio Layer-2 stellt eine Verbesserung des Layer-1 Coders dar und ist dementsprechendrecht ähnlich aufgebaut. Unterschiede bestehen in erster Linie in der Frame- und Blockeinteilung. Anders als beim Layer-1 Coder beinhaltet hierjedes Frame 1152 Abtastwerte, was einen Werteumfang von 36 Samples pro Block bei 32 Subbändern ergibt. Dies entspricht einer PCM-Signallänge von 24ms bei 48kHz. Da die zeitliche Länge eines Blockes jetzt deutlich größer ist, kann es Probleme mitder Maskierung durch den Skalenfaktor geben. Dessen Verdeckung wirkt schließlich wie oben bereits bemerkt nur für 20ms, füllt also denBlock nicht vollständig aus. Aus diesem Grund bestimmt der Layer-2 Coder zunächst die Anzahl der Skalenfaktoren, die für eine einwandfreie Wiedergewinnung der globalen Verdeckungsschwelle im gerade betrachteten Block nötig sind. In Audiosignalbereichen mit geringen zeitlichen Änderungen genügt ein Skalenfaktor, denn hier besitzen die drei errechneten Faktoren sehr ähnliche Werte. Die Rundungsfehler bleiben im Rahmen, wenn manstatt drei Skalenfaktoren nur einen abspeichert und diesen für den gesamten Block verwendet. Anders sieht es bei sich stark ändernden Eingangssignalen aus. Hier weisen die drei berechneten Faktoren große Wertunterschiede auf. Die drei Faktoren können nicht ohne weiteres durch einen Wert ersetzt werden, da dann die Rundungsfehler zu großesAusmaß besitzen würden. Daher verwendet man bei sich stark ändernden Signalen zwei oder gar drei Skalenfaktoren.MPEG Audio Layer-1 musste jede 12 Abtastwerte einen Skalenfaktor codieren. Bei Layer-2 reicht oft ein Faktor für 36 Abtastwerte.Es werden also eine ganze Reihe von Skalenfaktoren eingespart, was im Vergleich zum Layer-1 zu einer besseren Datenreduktion führt.
Eine zweite Veränderung gegenüber der Layer-1 Variante betrifft die Schaltung, die das Psychoakustische Modell bildet.Hier wird das Eingangssignal zwar ebenfalls mittels FFT in den Frequenzbereich transformiert, allerdings besitzt die FFT statt 512 jetzt 1024 Abtastwerte.Diese Steigerung bringt eine bessere Auflösung des Signals im Frequenzbereich und damit eine genauere Bestimmung der globalen Verdeckungsschwelle.
Eine weitere wichtige Neuerung besteht in beschränkten Quantisierungoptionen für Subbänder im obersten Frequenzbereich.Bänder im unteren Frequenzbereich können mit beliebigem Werteumfang zwischen 0 Werten und 65535 Werten, entsprechend bis zu 16 Bit, quantisiert werden.Der Layer-2 Encoder beschränkt diese Wahlmöglichkeit in Bändern hoher Frequenz drastisch. Hier kann das Signal nur mit vier verschiedenen Optionen(0, 3, 5 oder 65535 Werte) quantisiert werden. Der Vorteil dieser Taktik zeigt sich, wenn man sich die dynamische Bitzuweisung näher ansieht. Sie übermittelt dem Decoder unter anderem alle möglichen Quantisierungen, die für ein Band gemacht werden können. Erst wennder Decoder über diese Information verfügt, kann er herausfinden, welche Quantisierung in welchem Subband verwendet wurde und die Decodierung entsprechend darauf abstimmen.Um so mehr mögliche Quantisierungen nun für ein Band zugelassen werden, desto mehr Bit benötigt natürlich auch die Übertragung der Information, welche Quantisierungsoptionen auftreten können.Die obigen vier Optionen für den hohen Bandbereich benötigen für die Übertragung zum Decoder nur 2 Bit. Deutlich weniger also als beim Layer-1 Verfahren, wo auch für diese Bänder alle Optionen offen gehalten werden mussten.Klangliche Einschränkungen hervorgerufen durch diese Vorgehensweise sind kaum zu erwarten, da das Ohr wie im ersten Artikel "Digitale Audiocodierung - Teil I: Ansätze zur Datenreduktion" hier auf burosch.de erläutert wurdesehr hohe Frequenzen nur schlecht wahrnimmt.
Beträgt die Abtastrate des PCM-Signals 48kHz, so beinhalten die obersten Subbänder nur Signale mit Frequenzen oberhalb von 20kHz.Da diese unhörbar sind, löscht der Encoder die in diesen Bändern enthaltenen Daten vollständig, was eine gewaltige Dateneinsparung mit sich bringt. Layer-1 Decoder löschen diese Bänder unter Umständen nicht vollständig.
Layer-2 Encoder bereiten die über den Kanal zu übertragenden Daten vor der Multiplexbildung ferner noch speziell auf. Die Steuerdaten werden codiert (z.B. mittels Lauflängencodierung), diereduzierten Musikdaten durchlaufen eine zusätzliche Bit-Packing Stufe. Beides dient der optimalen Ausnutzung der zur Verfügung stehenden Übertragungsrate.
Codierung nach MPEG Audio Layer-3 (MP3)
Das MP3 Verfahren zur Datenreduktion bietet im Gegensatz zu den anderen Verfahren eine noch deutlich höhere Dateneinsparung. Allerdings ist dadurch der Decoder um einiges aufwendiger.
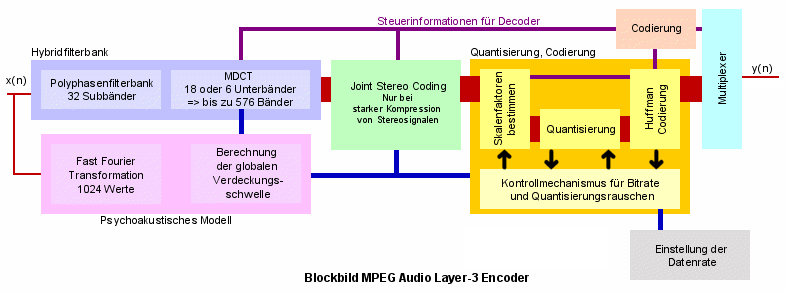
Das Eingangssignal durchläuft bei MP3 eine deutlich komplexere Filterbank, als bei den Layern 1 und 2. Diese als Hybridfilterbank bezeichneteKonstruktion besteht aus der von oben bereits bekannten Polyphasenfilterbank und einer nachgeschalteten Modifizierten Diskreten Cosinus Transformation (MDCT).Die Aufgabe der Polyphasenfilterbank besteht in der Zerlegung des Eingangssignals in 32 Subbänder. Sie wurde bei MP3 in erster Linie implementiert um die Kompatibilität zu denvorangegangenen Standards zu wahren.
Eine gewaltige Neuerung besteht in der nachgeschalteten MDCT. Diese dient der weiteren Zerlegung der einzelnenFrequenzbänder in insgesamt bis zu 576 Subbänder (Aufteilung jedes der 32 Bänder in weitere 18 Unterbänder). Da die Transformation verlustbehaftet ist, ist ein Ausgleich der in Aliasingverzerrungen hörbar werdenden Fehler nötig.Um diese Verzerrungen herauszurechnen überlappen sich die einzelnen Bänder.
Was bringt die Aufteilung in weitere Unterbänder? Zunächst einmal stellt man fest, dass dank der hohen Zahl der Subbänder eine enormeFrequenzauflösung vorhanden ist. Dies kann für sehr hohe Kompressionsraten genutzt werden. Leider hat die Sache einen Hacken.Grundsätzlich können Frequenz- und Zeitauflösung nie gleichzeitig sehr hoch sein. Ist die Frequenzauflösung hoch, so ist die Zeitauflösung entsprechend niedrig und umgekehrt.Ändert sich nun die Amplitude eines Signals sehr schnell, so kann diese Änderung aufgrund der geringen Zeitauflösung nicht richtig encodiert werden. Es entstehen Fehler wie hörbares Quantisierungsrauschen (Stichwort Pre-Echo).Aus diesem Grund muss der Coder das Signal daraufhin analysieren, ob es sich zeitlich rasch oder weniger rasch verändert. Ändert es sich rasch, so muss die mangelhafte zeitliche Auflösung der MDCT ausgeglichen werden.Die erste Möglichkeit besteht dabei in der Reduzierung der Unterbänder. Die Subbänder, entstanden durch die MDCT, werden auf 6 reduziert. Insgesamt existieren dann nur noch192 Frequenzbänder und die Frequenzauflösung ist dementsprechend schlechter. Daraus resultiert eine bessere Zeitauflösung und das Problem ist beseitigt. Allerdings ist bei dieser Taktik die maximal mögliche Kompressionsrate wiederum eingeschränkter, als beiVerwendung von 576 Bändern. Daher hat man sich bei MP3 noch eine weitere Möglichkeit einfallen lassen, um Fehler hervorgerufen durch geringe Zeitauflösung zu beseitigen.
Den Weg, den man einschlägt beruht darauf, dass sich Signalabschnitte mit geringer zeitlicher Änderung sehr stark komprimieren lassen. Unter Umständen so stark, dass man einige Bit bei vorgegebener Datenrate garnicht benötigt.Diese Bit werden in einem sogenannten Bit-Reservoir "zwischengelagert". In Signalabständen mit hohem Zeitauflösungsbedarf wird nicht etwa die MDCT auf 6 Subbänder heruntergefahren, sonderndie aufgesparten Bit dafür verwendet, das Signal so zu quantisieren, dass das aufgrund der schlechten Zeitauflösung entstehende Quantisierungsrauschen unter der globalen Verdeckungsschwelle liegt. Die Anzahl der in diesem Fall zu verwendenden Bit richtet sich nach Berechnungen des Psychoakustischen Modells.Auf diese Weise ist es möglich auch bei Signalanteilen mit hohem Zeitauflösungsbedarf mit hoher Kompression zu arbeiten. Nur bei Signalen, die eine extreme Zeitauflösung verlangen, schaltet MP3 zurück auf die MDCT mit 6 Unterbändern.
Der eigentliche Quantisierungs-/Codierungsprozess ist bei MP3 als Schleife ausgeführt. Eine innere Schleife (Inner Iteration Loop = Rate Loop) ist in eine äußere Schleife (Outer Iteration Loop = noise control/distortion loop) verschachtelt.Das eintreffende Signal gelangt zunächst in die äußere Schleife. Hier wird mit Hilfe der Skalenfaktoren die Quantisierung so eingestellt, dass das Quantisierungsrauschen unterhalb der globalen Verdeckungsschwelle liegt. Dazu werden zunächst Skalenfaktoren berechnet und mit diesen Skalenfaktoren und dem psychoakustischen Modell als Grundlagedas Signal quantisiert. Der nächste Schritt besteht aus einer Huffman-Codierung, die das quantisierte Signal weiter verlustfrei komprimiert. Anschließend wird die innere Schleife durchlaufen. Das vollständig kodierte Signal wird hier mit der maximalen Datenrate verglichen. Ist die Bitrate des Signals zu hoch,so wird das Signal global verstärkt, was einer Streckung der Quantisierungschrittweite und damit einer geringeren Bitrate gleichkommt. Schließlich entspricht die Bitrate einer bestimmten Bitanzahl pro Zeit. Wird die Zeit zwischen zwei Quantisierungswerten entsprechend gestreckt, so genügt in gleicher Zeit eine geringere Bitanzahl, um das Signal zu übertragen.Dieser Vorgang erfolgt solange, bis die Bitrate des Signals unterhalb der vorgegebenen Rate liegt.Nun wird überprüft, ob das Quantisierungsrauschen in allen Bändern unterhalb der globalen Verdeckungsschwelle liegt. Ist dies nicht der Fall, so müssen für dieses Band neue Skalenfaktoren bestimmt und die Werte erneut quantisiert werden (Rückkehr in die äußere Schleife).Anschließend erfolgt ein erneuter Durchlauf der inneren Schleife, bevor das Signal wiederum auf Quantisierungsrauschen überprüft wird. Dieser Vorgang wird so lange iteriert, bis das Signal rauschfrei ist und die vorgegebene Datenrate erreicht hat.
Anschließend kann das Signal wie bei den anderen Layern mittels Multiplexer in einen Bitstrom verschachtelt werden.
MP3 bietet die höchste Kompressionsrate der MPEG Audio Codecs. Ein Stereomusiksignal soll mit nur 128kBit/s CD-ähnliche Qualität erreichen.Für den durchschnittlichen Musikhörer, der Musik am PC oder im Auto hört ist diese Kompressionsstufe sicher ausreichend. Wer allerdings MP3 über eine hochwertigeHifianlage abspielen möchte, der sollte höhere Kompressionsraten ab 192kBit/s für Stereosignale verwenden. Tests im Profibereich haben gezeigt,dass ab einer Bitrate von 256kBit/s nicht einmal Fachleute MP3 Klänge und Musik von der CD unterscheiden konnten. Der optimale Einsatzbereich des Formats bleibt allerdings das Internet,wo es seinen eintscheidenden Vorteil - akzeptable Klangqualität bei extrem geringem Speicher- und Kanalkapazitätsbedarf - voll ausspielen kann.
Decodierung von MPEG Audio
Der Decoder für MPEG Audio ist sehr simpel aufgebaut. Der eintreffende Bitstrom wird in seine Bestandteile zerlegt und mit Hilfe derSteuerinformationen die Abtastwerte der einzelnen Frequenzbänder wiedergewonnen. Im letzten Schritt fügt eine inverse Filterbank dieeinzelnen Subbänder zu einem Audiosignal zusammen, das nach Digital-Analog-Wandlung und Verstärkung über die Lautsprecher ausgegeben werden kann.
Wie leicht ersichtlich liegt der technische Aufwand bei allen MPEG Audio-Verfahren nicht beim Decoder, sondern beim Encoder.Daraus resultieren zwei große Vorteile. Erstens können aufgrund der Simplizität des Decoders günstige Geräte für den Endverbraucher hergestellt werden. Schließlich steckt derLöwenanteil der Technik nicht in diesen Geräten, sondern im Encoder, der beispielsweise Teil von professionellen Sendeanlagen für digitalen Rundfunk ist.Der zweite große Vorteil besteht in der leichten Updatefähigkeit der Verfahren. Beispielsweise können neue Erkenntnisse über das psychoakustische Modell durch Austausch der entsprechenden Schaltung im Encoderberücksichtigt werden. Der Endverbraucher muss dagegen nicht auf ein neues Gerät umsteigen.
In den nachfolgenden Abschnitten wird jetzt näher auf MPEG 2 eingegangen, einem Codec zur Komprimierung mehrerer Tonkanäle.
Codierung/Decodierung nach MPEG 2
Im Gegensatz zu MPEG Audio lässt MPEG-2 auch Mehrkanalton zu. Bis zu drei Frontkanäle und zwei Surroundkanäle können verschlüsselt werden.MPEG-2 war in Europa zunächst als alleiniger Standard für die DVD vorgesehen, konnte sich dann aber nicht gegen das auf der Codierungstechnik AC-3 (Audio-Coding 3) basierende Dolby Digital der Dolby Laborathories Inc. durchsetzen. Diese Niederlage ist jedoch nicht auf mangelnde Qualität des Codierungsalgorithmusses von MPEG zurückzuführen, sondernauf mangelnde Unterstützung des Formats von Seiten der Endverbraucher und der Hersteller von DVD Hard- und Software. MPEG-2 könnte aber wieder interessant werden, wenn über digitales FernsehenMehrkanalton in großem Stil ausgestrahlt werden soll.
Oberstes Ziel bei der Entwicklung von MPEG 2 war die Erhaltung der vollen Kompatibilität zu MPEG Audio. Einerseits sollten neue MPEG 2 Audioinformationenproblemlos auf MPEG-Audio Decodern (in Stereo) wiedergegeben werden können, auf der anderen Seite sollten MPEG 2 Decoder auch MPEG Audio problemlos verarbeiten können.Nun bestand das Problem jedoch darin, dass mit dem neuen Verfahren fünf anstatt der bisher zwei Tonkanäle verschlüsselt werden mussten. Da MPEG Audio Decoder nicht für fünf Kanäle ausgelegt sind, mussten sich die Entwickler hier einige Kniffe einfallen lassen.
Um die Kompatibilität zu wahren beschloss man die zusätzlichen Tonkanäle im Encoder so zu verschlüsseln, dass nur MPEG 2 Decoder diese auswerten können. MPEG Audio Decoder sollten diese Informationen ignorierenund das Signal in Stereo ausgeben. Zunächst werden alle Kanäle mittels Matrixverfahren in ein Stereosignal verschachtelt. Für die entstehenden Stereokanäle Lo und Ro gilt folgendes:
Lo= Lf + aC + bL s L f = Front Links, C = Center, Ls = Surround Links
Ro= Rf + aC + bR sRf= Front Rechts, C = Center, Rs= Surround Rechts
Die beiden Konstanten a und b besitzen beim MPEG 2 Standard den Wert 0,71.
Bevor man sich näher mit der Unterbringung der einzelnen Kanäle im MPEG 2 Datenstrom befasst, muss man wissen,dass innerhalb eines MPEG Audio Layer-2 Bitstroms ein spezieller Bereich für Zusatzdaten existiert. Dieser Bereich wurde bei der Entwicklung von Layer-2bereits als Platzhalter für zukünftige Erweiterungen eingeführt. Gewöhnliche MPEG Audio Layer-2 Decoder werten diesen Zusatzteil nicht aus.
Die beiden Stereokanäle Lo und Ro werden nun bei der Codierung so behandelt, als wären sie ein gewöhnliches Stereosignal.Diese Kanäle werden nach Layer-2 datenreduziert und codiert. Die zusätzlichen Kanäle (Center und die beiden Surroundkanäle) werden ebenfallsnach Layer-2 encodiert und im Bereich für Zusatzdaten transportiert. Dabei speichert zusätzlich eine Joint Stereo ähnliche Codierung Übereinstimmungen in den Kanälen nur einmal ab, was eine sehr hohe Dateneinsparung mit sich bringt.Auf diese Weise wird auch bei fünf Kanälen die Datenrate im Zaum gehalten.
Trifft ein MPEG 2 Signal auf einen MPEG Audio Decoder, so wertet dieser dasStereosignal bestehend aus Lo und Ro aus und ein Stereosignal entsteht. Center und die beiden Surroundkanäle werden nicht erkannt, da sich diese im Zusatzdatenbereich befinden. Wenn der Bitstrom allerdings einen MPEG-2 Decoder durchläuft,so werden alle Kanäle ausgewertet, denn diese Decoder können den Zusatzteil einsehen.
Aber auch ein nach MPEG Audio codiertes Stereosignal stellt für einen MPEG 2 Decoder kein Problem dar. Findet der Decoder einenleeren Zusatzteil vor (bei MPEG Audio Layer 2 der Fall), so schaltet er auf Stereobetrieb um und das Signal wird in Stereo decodiert.
Quellenangaben:
- Fraunhofer Institut für Integrierte Schaltungen : Website mit Informationen zu den MPEG Codecs
- Audiocodierung von Philipp Straub
- HowStuffWorks : englische Website mit Informationen zu fast allen Technikbereichen
- MP3 von Patrick Preiner
- Coding Of Audiosignals
- Codierungssysteme mit Audiodatenreduktion : Diplomarbeit von Andi Schimmelpfennig
- Audiocodierung nach MPEG : Bearbeiter: Wolf Patrick
- MPEG video/audio compression : englische FAQ
- Digitale Fernsehtechnik. Datenkompression und Übertragung für DVB (Buch), von Ulrich Reimers, ISBN: 3540609458