Wissenswertes zur digitalen Audiocodierung und über bedeutsame Codecs, die nicht bzw. nicht nur zu den MPEG-Standards gehören. Im folgenden Artikel wird in diesem Zusammenhang zunächst auf ATRAC, anschließend auf AC-3 ("Dolby Digital") und zum Schluss auf AAC eingegangen.
Audiocodierung nach ATRAC
Die Abkürzung ATRAC steht für Adaptive Transform Acoustic Coding und wurde von Sony entwickelt. Sony setzt diesen ebenfalls auf der Psychoakustik basierenden Codec bei der Minidisk und bei SDDS, einem Mehrkanaltonverfahren im professionellen Kino ein. Das Verfahren erreicht dabei eine Kompressionsstärke von bis zu 5:1 bei annähernd CD-Niveau. Nur auf extremhochwertigen Wiedergabeketten kann ein Unterschied zwischen ATRAC und CD-PCM wahrgenommen werden. ATRAC erscheint mittlerweile in der fünften Version. Der Unterschied zwischen den einzelnen Versionen liegt in erster Linie in der Leistungsfähigkeit der Kompression und deren Qualität. Im folgenden soll ATRAC3 erklärt werden, da dieses Verfahren im Moment am verbreitetsten ist. Insbesondere der Aufbau des Encoders kann bei anderen Versionen in Einzelheiten unterschiedlich ausfallen, alle Verfahren basieren jedoch auf den gleichen grundlegenden Techniken.
Der ATRAC-Encoder:
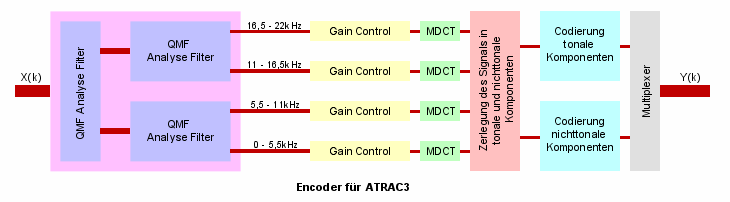
Das eintreffende digitale PCM-Audiosignal X(k) durchläuft zunächst einen Analysefilter. Dieser spaltet das Signal mittels Quadratur Mirror Filter (QMF) in vier Teilbänder auf (ältere ATRAC-Versionen verwendeten drei Bänder). QMF-Filter haben den Vorteil, dass entstehendes Aliasing im Zeitbereich bei der Decodierung automatisch korrigiert werden kann. Der Frequenzumfang der einzelnen Subbänder ist im obigen Blockschaltbild angegeben.
In einer nächsten Stufe durchläuft jedes Band separat einen Gain-Control-Block (Gain = engl. Verstärkung). Um die Funktion dieses Teilstückes zu verstehen, muss man wissen, dass ATRAC wie jeder Codec der Subbands verwendet, Probleme mit sich zeitlich sehr schnell ändernden Signalen hat. Direkt bevor eine solche Signaländerung auftritt, kann es im Encodierungs-/Decodierungsprozess durch Quantisierungsungenauigkeiten zu Klangverfälschungen, so genannten "Pre-Echos" kommen. Diese Art der Verzerrung kann mit Hilfe einer Anpassung der Amplitude des Audiosignals im betreffenden Zeitabschnitt kompensiert werden. Gain Control verstärkt den Signalabschnitt vor jeder plötzlichen zeitlichen Änderung der Audioinformation während der Encodierung. Bei der Decodierung wird das Signal und damit Quantisierungsfehler wieder entsprechend abgeschwächt und damit hörbare Verzerrungen vermieden.
In der nächsten Stufe werden die Informationen der Teilbänder jeweils mittels einer modifizierten diskreten Kosinus Transformation blockweise in den Frequenzbereich übertragen. Die Länge der einzelnen Transformationsblöcke kann dabei variiert werden. Man unterscheidet einen long mode (11,6ms Länge) und einen short mode (1,4 - 2,9ms Länge). Standardmäßig wird der long modeverwendet, in kritischen Passagen wird jedoch auf den short mode zurückgeschaltet. Insbesondere stellt der short mode eine weitere Möglichkeit zur Bekämpfung der Pre-Echos dar. Jede der vier MDCT weist einen Signalumfang von 256 Werten auf, was insgesamt einer 1024 Punkte MDCT entspricht (ältere ATRAC-Versionen arbeiteten mit geringerer Auflösung). Im Frequenzbereich erfolgt nun eine genaue Analyse der Signalkomponenten im Bezug auf die Tonalität. Auf Basis der Tonalität eines Signals entscheidet der ATRAC-Coder, ob Signalanteile kritisch bzw. unkritisch im Bezug auf die Wahrnehmung durch das menschliche Ohr sind. Im Frequenzbereich flach verlaufende Signale gelten als unkritisch. Die Bitaufwendung für solche Informationsabschnitte ist entsprechend niedrig. Signale, die eine hohe Tonalität im Frequenzbereich besitzen müssen dagegen mit hoher Bitrate codiert werden. Diese kritischen Bereiche werden mittels Entropy Coding verschlüsselt (Huffman Coding). Unkritische Anteile dagegen können mit höherer Kompression abgesichert werden.
Um eine besonders hohe Kompressionsrate zu erreichen wird bei ATRAC3 ähnlich wie bei MP3 zusätzlich eine Joint-Stereo Codierung vorgenommen. Diese führt insbesondere in monauralen Abschnitten zu enormen Datenersparnissen.
Abschließend sorgt ein Multiplexer für die Verschachtelung der komprimierten und codierten Audiodaten sowie der Steuerdaten für den Decoderin einen Bitstream Y(k), der dann über einen Kanal verschickt, oder wie im Falle der Minidisk und SDDS auf Tonträger aufgezeichnet werden kann.
Der ATRAC-Decoder:
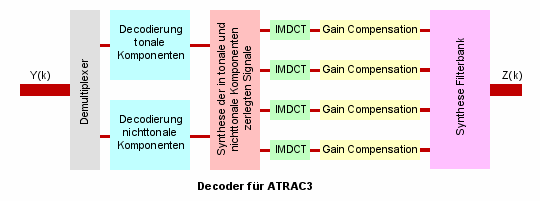
Dem Decoder obliegt wie bei allen Codierungstechniken die Wiederherstellung des Originalsignals soweit möglich. Zunächst werden im Demultiplexer die einzelnen Informationsdatenstränge (Steuerinformationen dür den Decoder und Audioinformation) aus dem ankommenden Bitstream Y(k) gewonnen. Die Steuerinformation ermöglichst es dem Decoder anschließend die Audioinformationen zu decodieren und die vier Subbänder durch eine Syntheseschaltung wiederherzustellen. Die inversen modifizierten diskreten Kosinus Transformationen (IMDCT) gestatten eine Rückführung des Signals in den Zeitbereich. Anschließend wird in der Gain Compensation die während des Codierungsprozesses an kritischen Stellen hinzugefügte Verstärkung kompensiert. Abschließend sorgt eine Synthesefilterbank für den Zusammenschluss der vier Teilbänder zu einem Audioausgangssignal Z(k).
Audiocodierung nach AC3
Der Codec AC3 (Audio Codec 3) wurde von den Dolby Laborathories Ltd. entwickelt und wird im amerikanischen digitalen Fernsehen und im Kino eingesetzt. Der Codec kann bis zu 5 diskrete Fullrange-Kanäle und einen Subwooferkanal in hoher Klangqualität und niedriger Bitrate (minimal 320kBit/s) verschlüsseln. Das Kompressionsverhältnis erreicht dabei 13:1.AC3, auch bekannt unter dem Namen Dolby Digital, ist auch Tonstandard bei der DVD. Im digitalen Fernsehen in Europa könnte er sich ebenfalls etablieren. Zunächst zum Aufbau des Encoders:
Der AC3 Encoder:
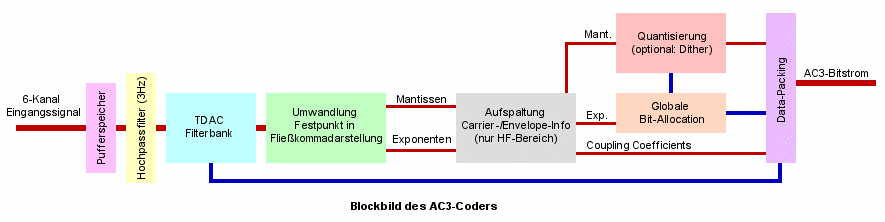
Das PCM-Eingangssignal jedes Kanals gelangt im AC3-Coder zunächst in einen Eingangspufferspeicher. Aus diesem Speicher werden die digitalen Daten blockweise weiterverarbeitet. Ein Block umfasst dabei im Zeitbereich 512 Abtastwerte. Ein Hochpassfilter bei 3Hz sorgt in der nächsten Stufe für die Eliminierung von Gleichspannungsanteilen. Ferner wird hier der Subwooferkanal mit 120Hz Grenzfrequenz tiefpassgefiltert.
Das Signal wird nun zur weiteren Bearbeitung vom Zeit- in den Frequenzbereich transformiert. Als Transformation dient eine sogenannte TDAC-Filterbank (Time Domain Aliasing Cancellation), die das Frequenzspektrum in mehrere Subbänder unterteilt. Sie enthält eine FFT (Fast Fourier Transformation), die Blöcke bestehend aus 512 bzw. 256 Abtastwerten in den Frequenzbereich transformiert. Die lange Transformation (512 Werte) wird dabei in Signalabschnitten mit geringer zeitlicher Änderung eingesetzt, die kurze Transformation (256 Werte) kann dank größerer Zeitauflösung auch sich zeitlich schnell ändernde Signalabschnitte ohne große Verluste transformieren. Natürlich muss dem Decoder mitgeteilt werden, welche Transformation stattgefunden hat. Aus diesem Grund werden entsprechende Steuerdaten an den AC3-Decoder übertragen.
Die einzelnen transformierten Blöcke überlagern sich um 50%. Dies gewährleistet eine optimale Codierung ohneFehler an den Blockgrenzen.
Die mittels FFT gewonnenen Koeffizienten des Signals im Frequenzbereich werden bei AC3 nicht als Festpunktzahlen weiterverarbeitet sondern nach folgender Formel indie Gleitkommadarstellung umgerechnet: Festpunktzahl = M * 2E
Durch mathematische Überlegungen lässt sich herausfinden, dass der Exponent E einen Wert zwischen 0 und 24 aufweisen muss. Die Mantisse M besitzt dann Werte zwischen 0,5 und 1. Der Vorteil der Gleitkommadarstellung liegt beispielsweise darin, dass keine führenden Nullen von Zahlen dargestellt werden müssen. Außerdem wird der Dynamikumfang des Signals während der Weiterverarbeitung so gut wie nicht eingeschränkt. Auf diese Weise kann AC3 selbst die Fähigkeiten hochwertiger 18-22Bit A/D- und D/A-Wandler voll ausschöpfen. Als netter Nebeneffekt führt die Gleitkommadarstellung zu leichterer Handhabbarkeit der Bit-Allocation, einer weiteren Prozesseinheit des AC3-Coders.
Ein Ansatz zur Datenreduktion unter Ausnutzung der Gehöreigenschaften des Menschen besteht im Bereich hoher Frequenzen. Das Ohr kann hier nicht den exakten Verlauf der Audiowelle aus dem Signal extrahieren, sondern nur seine Frequenz-Zeit-Einhüllende wahrnehmen. Aus diesem Grund werden hochfrequente Signale bei AC3 in eine Carrierinformation und Information, die die Einhüllende betreffen, aufgespalten. Zweiterer Anteil wird als "Envelope" bezeichnet. Da die Envelopes wichtige Daten enthalten, werden sie mit hoher Bitrate quantisiert und als "coupling coefficients" an den Decoder übertragen. Die Carrierinformation kann dagegen mit geringer Bitrate gesichert werden. Sie wird den vorher gewonnenen Exponenten und Mantissen zur Übertragung beigefügt. Die Carriersignale der 5.1 Kanäle können ferner oft zu einer Dateneinheit zusammengefügt werden. Dadurch ist eine Verringerung der Redundanz im Bereich hoher Frequenzen möglich. Dieses Vorgehen wird auch als Kopplung bezeichnet, da hier mehrere Kanäle über Carriersignale gekoppelt sind. Natürlich muss auch hier der Decoder über das Vorgehen beim Encodierungsprozess informiert werden. Der Umfang und die Art der Kopplung wird daher an den Decoder übertragen.
Der nächste Schritt besteht in der globalen Bit-Allocation. Hier wird die eigentliche Datenreduktion vorgenommen. Die Koeffizienten der TDAC-Filterbank (Exponenten und Mantissen) werden mitdem psychoakustischen Modell verglichen und an Hand der daraus folgenden Informationen die optimale Bitrate für die Mantissen errechnet. Die Exponenten dienen als Skalenfaktoren für die zugehörigen Mantissen.Wichtig ist dabei, dass die 5.1 Kanäle nicht getrennt betrachtet werden, sondern im Hinblick auf Redundanz und Unterschieden zwischen ihnen. Auf diese Weise kann die Bitrate in Kanälen, wo momentan hohe Informationsdichte benötigt wird hochgefahren werden, während die anderen Kanäle mit niedriger Bitrate codiert werden.Die globale Bitrate kann durch unterschiedliche Bitraten in den Einzelkanälen konstant gehalten werden.
Ferner ist auch ein Einbezug einer Hörschwelle über alle Kanäle möglich. Schließlich überdeckt ein lauter Kanal andere Kanäle, die Audioinformationen wesentlich leiser wiedergeben. Dadurch kann in von anderen Kanälen akustisch überdeckten Kanälen die Datenrate heruntergefahren werden. In der Praxis hat sich allerdingsgezeigt, dass dieser Effekt der Interkanalverdeckung stark von der Hörposition abhängt und daher nur begrenzt ausgenützt werden kann.
Die Information auf welche Art und Weise die Bit-Allocation stattgefunden hat wird wiederum an den Decoder übertragen.
Nun erfolgt die Quantisierung der voher normierten Mantissen. Der Grund für die Normierung liegt in erster Linie in dergeringeren Anfälligkeit der Daten für Verzerrungen und der besseren Vorbereitung auf eine eventuell neben der Quantisierung herlaufende Verwendung von Dither. Der Nachteil der Normierung liegt ganz klar darin, dass auch hierfür wieder Steuerdaten für den Decoder anfallen. Diese werden benötigt, um die tatsächlichen Werte der Mantissen im Decodierungsprozess wiedergewinnen zu können.
Der letzte Prozess innerhalb des AC3 Coders ist die Verpackung der bis hierher gesammelten Daten in einen gemeinsamen AC3 Bitstrom (Data Packing). Zusätzlich werden noch einige Bit an Fehlerkorrektur sowie Synchronisierungsinformationen beigefügt.
Der AC3-Decoder
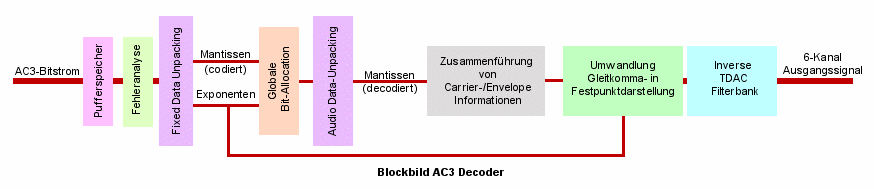
Wie der Encoder ist auch der Decoder blockstrukturiert. Ein Pufferspeicher am Eingang sorgt zunächst fürgenügend Speicherplatz, um einzelne Datenblöcke des eintreffenden Bitstreams einzulesen und dann am Stück zu verarbeiten. Es folgt eine Prozedur, die Fehler im ankommenden Block ausfindig macht und sofern nötig korrigiert. Bei Fehlern, die aus irgendeinem Grund nicht korrigiert werden können besitzt der Decoder mehrere Optionen, um mit seiner Arbeit fortfahren zu können. Eine Möglichkeit ist die Wiederholung des letzten als korrekt eingestuften Blockes bis zu dem Zeitpunkt, an dem ein Block eintrifft, der keine Fehler mehr aufweist. Allerdings kann diese Wiederholung nicht endlos weiterlaufen. Im Extremfall schaltet der Decoder komplett auf stumm oder verwendet im Kino die optional auf dem Filmmaterial aufgebrachte analoge Tonspur.
In der Fixed Data Unpacking Stufe werden zunächst die Steuerinformationen, die Coupling Coefficients sowie dieaus der Bit-Allocation des Coders stammenden Exponenten zurückgewonnen.
Durch eine inverse Bit-Allocation und eine Unpacking Stufe für die Audiodaten stellt der Decoder mit Hilfe der aus der Fixed Data Unpacking Stufe gewonnenen Informationen im nächsten Schritt die tatsächlichen Werte der Mantissen wieder her. Die optimale Abstimmung zwischen Decoder- und Encoder-Bit-Allocation ist dank der übermittelten Steuer- und Synchronisationsdaten gewährleistet. Falls Dither verwendet wurde wird dieser hier ebenfalls rückgängig gemacht. Die ursprünglichen Koeffizienten der TDAC-Filterbank werden aus Carrier-Informationen und Envelopes wiedergewonnen und gleichzeitig eine eventuell vorhandene Kopplung zwischen den Kanälen aufgehoben.
Da die Koeffizienten der TDAC Filterbank des Coders jedoch aus Exponent und Mantisse bestehen werden diese nun wieder zu einer Einheit zusammengeführt und anschließendvon der Gleitkommadarstellung in die Festpunktdarstellung umgerechnet.
Abschließend sorgt eine inverse TDAC-Filterbank für die Rückführung des Signals von der Frequenz- in die Zeitebene.
Audiocodierung nach MPEG-2 Advanced Audio Coding AAC: AAC (Advanced Audio Coding) ist die neuste Entwicklung unter der Federführung der MPEG im Bereich der Audiodatenreduzierung und wurde ursprünglich mit dem Namen MPEG-2 NBC (Non Backwards Compatible) versehen.Man verzichtete bei MPEG darauf das Verfahren kompatibel zu den bisherigen MPEG-Standards zu halten, stattdessen wurden gute Ansätze aus allen bisherigen Codecs zur Audiodatenreduzierung verwendet. Insbesondere die Frauenhofer Gesellschaft (MP3), Dolby (AC3), Sony (ATRAC) und AT&T wurden zur Mitarbeit gewonnen. Herausgekommen ist ein Codec mit nie dagewesener Leistungsfähigkeit.Bis zu 48 Audiokanäle können mit einer Samplingrate zwischen 8kHz und 96kHz sowie Bitraten zwischen 16kbit/s und 576 kbit/s codiert werden. Soll CD-Klangqualität erreicht werden, so ist AAC doppelt so effektiv wie MPEG-1 Audio Layer 2 und 1,4 mal so effektiv wie MP3.Aufgrund seiner Komplexität ist AAC allerdings rechenintensiv. Sinnvoll einzusetzen ist AAC erst ab Computersystemen mit einer Rechenleistung vergleichbar einem P2-300.
Um auch auf weniger leistungsfähigen Rechnern AAC einzusetzen, steht AAC in verschiedenen Varianten zur Verfügung (sogenannte Profiles). Man unterscheidet die folgenden Profiles:
- Main Profile: das Profil mit den höchsten Anforderungen und gleichzeitig den besten Klangergebnissen. Nachteil: hohe Komplexität, hohe Rechenleistung und viel Arbeitsspeicher erforderlich (Strukturen von AAC vollständig, aber ohne "Gain-Controll" - siehe auch ATRAC)
- Low-complexity Profile: deutlich abgespeckte Variante, die nicht so gute Klangergebnisse zeigt, dafür aber deutlich geringere Anforderungen an das Rechnersystem stellt (Keine Prädiktion, temporal noise-shaping eingeschränkt)
- Samplerate Scaleable (SRS) Profile: Low-complexity Profile mit zusätzlichem Gain-Controll, geringster Implementierungsaufwand für Coder und Decoder
Der AAC-Encoder:
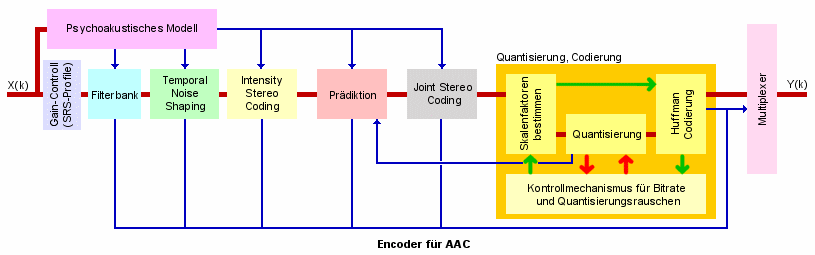
Die erste Stufe innerhalb des AAC-Coders liegt wie bei den bisherigen Verfahren in einer Filterbank. Diese teilt das eintreffende Signal in Blöcke zu 2048 bzw. 256 Abtastwerte (Long Blocks, Short Blocks) und transformiert diese anschließend mit Hilfe einer modifizierten Kosinus Transformation (MDCT) in den Frequenzbereich. Die kurzen Blöcke werden ähnlich wie beispielsweise bei AC3 dann verwendet, wenn sich das Eingangssignal im Zeitbereich schnell ändert. Hier wird hohe Zeitauflösung verlangt, was durch die kurze Blocklänge gewährleistet ist.
Lange Blöcke werden natürlich dann eingesetzt, wenn die zeitliche Änderung des Signals gering ist. Im Gegensatz zu bisherigen Codecs offeriert AAC zwei verschiedene Modi, in denen derLong Mode gefahren werden kann. Auf der einen Seite kann der Block mittels Sinusfunktion erzeugt werden, auf der anderen Seite mit Hilfe einer abgeleiteten Kaiser-Bessel-Funktion. Die Sinusfunktion wird immer dann verwendet, wenn die spektralen Werte des Eingangssignals sehr dicht beieinander liegen. Die Kaiser-Bessel-Funktion dagegen ist dort optimal eingesetzt, wo die Werte des Spektrums weit entfernt voneinander sind.
Ein bei AAC neu hinzugekommener Prozessschritt besteht im "Temporal Noise Shaping" (TNS). Temporal Noise Shaping ist eine Technik, die es erlaubt Quantisierungsrauschen im Zeitbereich so zu positionieren, dass es durch Maskierungseffekte (berechnet nach einem psychoakustischen Modell) verdeckt wird. Ermöglicht wird dies durch eine Vorhersage der zeitlichen Rauschverteilung aufgrund der Werteverteilung im Frequenzbereich. Insbesondere Stimmen klingen dank TNS realistischer und detailgetreuer.
Bei der Codierung des Hochtonbereichs berücksichtigt der AAC-Coder ähnlich wie der AC3 Coder, dass das menschliche Gehör in diesen Bereichenin erster Linie kritisch auf die Frequenz-Zeit-Einhüllende von Schallwellen reagiert. Diese Tatsache kann bei der Codierung dazu genutzt werden, um die Hochtoninformation mehrerer Kanäle in den gleichen spektralen Werten zu sichern.Diese müssen nur einmal abgespeichert werden, wodurch sich eine drastische Dateneinsparung ergibt. Wie bei AC3 ist der klangliche Qualitätsverlust bei dieser auch als "Intensity Stereo Coding" bezeichneten Vorgehensweise extrem gering.
Als nächstes folgt eine Prädiktionscodierung. Diese Taktik ist im Audiobereich eine der weiteren Neuerungen von AAC. Im Gegensatz zu den übrigen Codecs beschränkt sich AAC nicht auf die Betrachtung der Daten innerhalb eines Blockes, sondern untersucht das Audiosignal blockübergreifend auf Redundanz und Irrelevanz. Sich in mehreren aufeinanderfolgenden Blöcken wiederholende Information muss so nicht jedesmal neu abgespeichert werden. Es genügt für Blöcke, in denen die Information wieder auftaucht einen Hinweis zu hinterlassen, wieviele Blöcke vorher diese Information zu finden ist. Da sich das Signal innerhalb von short blocks sehr schnell ändert (aus diesem Grund verwendete man ja short blocks), würde Prädiktion hier keinen Effekt bringen. Hier sind die Übereinstimmungen zwischen mehreren Blöcken einfach zu gering. Daher wird im AAC-Codec Prädiktion nur im Bereich der long blocks verwendet. Im Detail handelt es sich bei der hier angewendeten Prädiktion um eine "backward adaptive linear prediction", die immer zwei vorhergehende Blöcke mit dem gerade aktuellen Block vergleicht.
Auch die Joint-Stereo-Codierung findet bei AAC in einer leicht abgewandelten Variante statt (Mid/Side Stereo-Coding). Der AAC-Coder untersucht während der Codierung, ob es sinnvoller ist Joint-Stereo-Coding anzuwenden, oder nicht. Kann mit Joint-Stereo-Coding eine geringere Datenrate erzielt werden,so wird dieses Verfahren angewendet. Dem Decoder wird eine entsprechende Information mitgeliefert, dass die nun folgenden Daten mit Joint-Stereo reduziert wurden. Auf diese Weise ist eine korrekte Wiederherstellung des Originals gewährleistet.
Der nun folgende Quantisierungs-/Codierungsprozess erfolgt nach dem gleichen Schema, wie auch bei MP3. Mit Hilfe einer inneren und einer äußeren Wiederholungsschleife wird durch Quantisierung und Codierungdie optimale Bitrate eingestellt. Hier wird auch das psychoakustische Modell einbezogen. Noiseless Coding (Huffman Coding) wird zusätzlich als verlustfreie Komprimierung herangezogen. Eine genauere Analyse des Quantisierungs-/Codierungsprozesses finden Sie im 2.Teil dieses Fortsetzungsartikels "Digitale Audiocodierung - Teil II: MPEG Codecs" hier auf http://www.burosch.de
Abschließend verpackt der AAC-Coder Audio- und Steuerdaten mittels Multiplexer in einen Bitstrom.
Der Decodierungsprozess kehrt bei AAC wie auch bei allen anderen Codecs die während der Encodierung vorgenommenen Signaländerungen sofern möglich wieder um und extrahiert aus den vorhandenen Daten das digitale Ausgangssignal.
Fazit
In den drei Teilabschnitten zur digitalen Audiocodierung wurden grundlegende Verfahren, sowie die wichtigsten Codecs vorgestellt.Leider konnte das sehr umfassende Thema nicht in allen Einzelheiten durchleuchtet werden. Das würde den Rahmen einer Internetseite deutlich sprengen.Wer sich weiter in dieses Thema einarbeiten möchte, dem seien im Internet die unten stehenden Quellenangaben empfohlen. Auf vielen dieser Seiten finden Sie auch Hinweise aufdie entsprechende Fachliteratur. Wir hoffen, dass Sie mit unserem Fortsetzungsartikel trotz aller Knappheit einen kleinen Einblick in die Technik moderner Audio-Coder und Decoder bekommen konnten.
Autor: